I can’t talk about important intelligence concepts for security without talking about the grand daddy, the original: the Intelligence Cycle. This should be great discussion fodder for anyone who has to talk to someone who claims they’re selling some form of Threat Intelligence product, given in most cases they seem to be using the phrase in place of the word smart. Intelligence vs smart couldn’t be farther from the truth.
The Intelligence Cycle
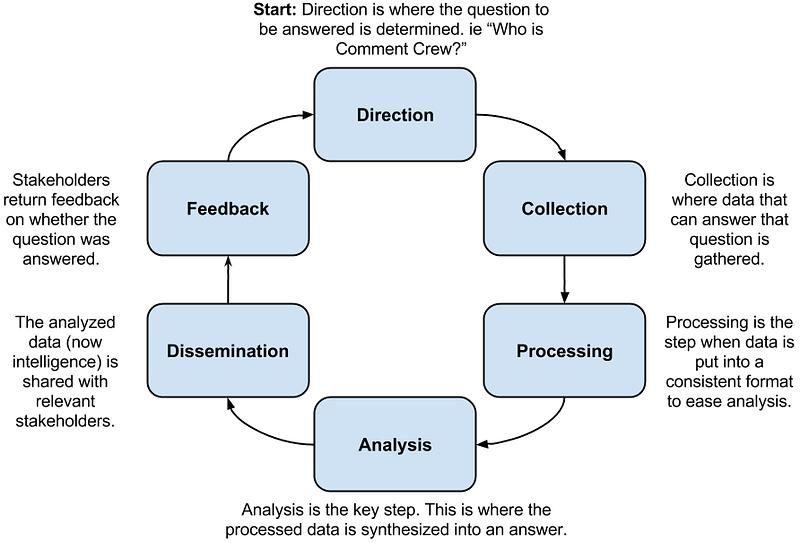
That’s it. Six steps described in six sentences, all pretty straight forward and clear. How could this get so misconstrued?
The Intelligence Cycle in Incident Response
For the last two or so years the security industry has been all about Threat Intelligence with almost no idea what the word intelligence actually means. Companies using the word intelligence are trying to say something involves an intelligent concept. Some of these technologies are innovative and beneficial, but they aren’t intelligence. The desire is to cash in on the current (and ambiguous) threat intelligence trend and thus everything is intelligence.
Both intelligence in the Intelligence Process sense and the smart sense are valid, but have distinctive connotations. The problem is marketing and a desire to cash in on the threat intelligence trend has resulted in vendors manipulating potential customers by confusing these meanings.
Vendors are selling data feeds, management platforms, actor reports, vulnerability centric reports, and tools, but none of these are intelligence. In every case they are a piece, often important pieces, but not a whole. The whole of threat intelligence takes tools, data sources, people, and processes dedicated to collecting in all those inputs and contextualizing them by working through the intelligence process.
A Walk Through the Intelligence Cycle
I track groups for my own interest and work through this cycle often. In this case we’re going to walk through this cycle the way I would for one of the more infamous groups out there; the infamous Comment Crew aka APT1.
Direction
First we have to set the parameters of what questions we’re trying to answer. When I’m doing my personal research I generally have two goals:
- A general understanding of a group such as their goals.
- Any indicators of compromise that could help me identify this group.
Collection
Collection is the process of gathering as much information as you can that can help answer the questions posed in direction. My first thought with groups like is to create a series of search terms or known data point to start our collection of of.
Aside: The most difficult data point to gather at the start of an investigation is all the potential reference terms for a specific group. Comment Crew is also called Soy Sauce, ShadyRat, WebC2, GIF89a, APT1, Comment Panda, and their Military Unit Cover Designator Unit 61398, all depending on who you ask. At this point each vendor has their own name, and each “fight club” often has their own designator as well. I’m stunned how often I’ve missed information about an actor just because I was too focused on the wrong name.
From there we have a couple common sources:
- Google: It’s amazing what you can find going through articles & blog posts. You’ll want to store all the, though watch out; the current tech media is rife with republishing all over the place.
- Vendor Information: Comment Crew was the focus of the most prolific single vendor report in security community history. This of course merited a walk through with a fine tooth comb, but so did the follow on reports as well.
- Re-Analyzing Information: From this point there’s a whole new series indicators of compromise as well as non-technical indicators such as associated actor names, the actual unit designator of the group, etc. Each of these in turn is the basis of another collection using other sources. This is where tools like DomainTools, VirusTotal, and PassiveTotal become handy.
The collection process continues until exhausted, either based on content or on time.
Processing
At this point you have a mountain of data. Processing is taking all this data and putting it into useful formats for further analysis. This is all about consistency and ease of analysis. This is one of the toughest problems in the security space right now and has resulted in a lot of competing solutions (CRITs, MISP, ThreatConnect, ThreatQuotient, and dozens of home grown systems).
I end up processing my data into a lot of formats. For things like reports and articles I initially process them into JSON files per article. From there I push my data (Note: I’m saying data, not intelligence yet) into two primary places; my personal instance of CRITs intelligence management system and a git repository where I keep my processed JSON, CSV, and Markdown files. Maltego for graphical analysis. I also keep all my raw, but processed files around in case I need to manipulate them differently later.
Analysis
Now we have the necessary collection of data processed into a consistent manner and we’re ready to go back and address those original questions.
- A general understanding of a group such as their goals? This is what the long form reports tell us. And for a case like this we’re looking for confirmation from more than one source. We learn this group is about attacking military related targets, trying to gather information that will support their national defense.
- Any indicators of compromise that could help identify Comment Crew? At this point you have thousands of indicators, IPs, hashes, malware, domain names, etc. The key for analyzing these isn’t just having them, but having them in useful formats. This means formatting (we’ll get into that in dissemination) but also deconfliction, making sure that you understand the context of the indicators you have.
Aside on Deconfliction: Plenty of pieces of malware beacon to well known sites/IPs to make sure they’re connected to the Internet. You don’t want to report 8.8.4.4 (Google DNS) is a malicious IP. At the same time identifying a malware characteristic found in 100% of a groups malware is great, unless it’s also found in 100% of all PE files (
MZ).
That’s the basic analysis process. My products for something like this generally include a couple paragraphs to answer the first question, to be continually updated, and a group of files detailing the second set of indicators. I could use on one of the major standards for that, such as STIXX or OpenIOC, but given at this point they’re both difficult to work with and not well adopted I find its easier to stick with open file types like Markdown, JSON, CSV, etc.
Dissemination
The next to last step is dissemination to stakeholders. In a case like this I’m the stakeholder, so I don’t need things disseminated as this is a reference set for me. In the event I was building this for someone else this is the point where I’d pass them information.
If I was disseminating this data there are things to consider:
- Different stakeholders will need a different format of product: Engineers and analysts will want indicators in easy to work with formats (like JSON & CSV). Managers and directors will want shorter briefs, often in prose, and probably as PDFs. Always consider your audience in how you share your data.
- Operational security of intelligence matters: The TLP method helps, but you have to make sure people will follow through with this. You don’t want to do all this work compromised group you’re analyzing.
Feedback
The feedback step is the simplest part of this whole cycle: Did you answer the questions posted during direction to the stakeholders satisfaction? If yes does this lead to new questions/direction? If no how does this lead to generating a better question or a new series of collections?
This is a tough one to stomach. If you’re the stakeholder you’re answering to yourself, which makes it difficult to be honest in your assessment. If the stakeholder is someone else this is their chance to judge your work. Brutal honesty with yourself throughout the process is the answer.
The other key piece of feedback is how application of the new intelligence you’ve developed results in even more data. Say you deploy a snort rule for a network string and you get a hit, all the information you can gather around that hit is data to include during the collection phase of your next cycle. We’ll talk even more about this integration in my next post on F3EAD.
Takeaways from the Intelligence Cycle
The intelligence cycle isn’t something that gets used day in and day out in DFIR work, but is becoming more and more critical to always have running in the back of your head. Whether evaluating new tools or vendors its important to understand that intelligence isn’t just data, it’s data processed in a rigorous way to ensure a balanced, well contextualized product. This is to make sure you’re making good decisions, not following whatever data is in front of you.